 ## 创建hadoop用户
1. 创建用户hadoop,并且用/bin/bash作为默认shell:
johnathon@ubuntu16:~$ sudo useradd -m hadoop -s /bin/bash
2. 为用户hadoop设置密码:
johnathon@ubuntu16:~$ sudo passwd hadoop
3. 将用户hadoop加入sudo组:
johnathon@ubuntu16:~$ sudo adduser hadoop sudo
## 创建hadoop用户
1. 创建用户hadoop,并且用/bin/bash作为默认shell:
johnathon@ubuntu16:~$ sudo useradd -m hadoop -s /bin/bash
2. 为用户hadoop设置密码:
johnathon@ubuntu16:~$ sudo passwd hadoop
3. 将用户hadoop加入sudo组:
johnathon@ubuntu16:~$ sudo adduser hadoop sudo
更新apt
hadoop@ubuntu16:~$ sudo apt-get update
配置ssh免密登陆
- 安装ssh服务
hadoop@ubuntu16:~$ sudo apt-get install ssh - 创建.ssh目录
hadoop@ubuntu16:~$ cd ~ hadoop@ubuntu16:~$ mkdir .ssh - 生成ssh密钥
hadoop@ubuntu16:~$ cd .ssh/ hadoop@ubuntu16:~$ ssh-keygen -t rsa hadoop@ubuntu16:~/.ssh$ cat id_rsa.pub >> authorized_keys - ssh登陆localhost
hadoop@ubuntu16:~/.ssh$ cd hadoop@ubuntu16:~$ ssh localhost - 退出ssh登陆
hadoop@ubuntu16:~$ exit logout Connection to localhost closed.
安装配置jdk
安装hadoop
解压hadoop安装文件到相应的目录
hadoop@ubuntu16:~$ sudo tar -zxf hadoop-2.8.0.tar.gz -C /usr/local给hadoop目录重命名
hadoop@ubuntu16:~$ cd /usr/local hadoop@ubuntu16:/usr/local$ sudo mv hadoop-2.8.0/ hadoop将hadoop目录用户改为hadoop
hadoop@ubuntu16:/usr/local$ sudo chown -R hadoop hadoop/查看hadoop目录
hadoop@ubuntu16:/usr/local$ cd hadoop/ hadoop@ubuntu16:/usr/local/hadoop$ ls -l total 148 -rw-r--r-- 1 hadoop dialout 99253 Mar 17 13:31 LICENSE.txt -rw-r--r-- 1 hadoop dialout 15915 Mar 17 13:31 NOTICE.txt -rw-r--r-- 1 hadoop dialout 1366 Mar 17 13:31 README.txt drwxr-xr-x 2 hadoop dialout 4096 Mar 17 13:31 bin drwxr-xr-x 3 hadoop dialout 4096 Mar 17 13:31 etc drwxr-xr-x 2 hadoop dialout 4096 Mar 17 13:31 include drwxr-xr-x 3 hadoop dialout 4096 Mar 17 13:31 lib drwxr-xr-x 2 hadoop dialout 4096 Mar 17 13:31 libexec drwxr-xr-x 2 hadoop dialout 4096 Mar 17 13:31 sbin drwxr-xr-x 4 hadoop dialout 4096 Mar 17 13:31 share查看hadoop版本信息
hadoop@ubuntu16:/usr/local/hadoop$ ./bin/hadoop version Hadoop 2.8.0 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 91f2b7a13d1e97be65db92ddabc627cc29ac0009 Compiled by jdu on 2017-03-17T04:12Z Compiled with protoc 2.5.0 From source with checksum 60125541c2b3e266cbf3becc5bda666 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.8.0.jar设置hadoop环境变量
6.1. 打开hadoop用户下配置文件hadoop@ubuntu16:~$ vi .bashrc6.2. 编辑文件,添加如下
#set hadoop env begin export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$JAVA_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin #set hadoop env end6.3. 使文件修改生效
hadoop@ubuntu16:~$ source .bashrc6.4. 查看hadoop版本信息(注意:与上一步骤中查看版本信息的区别)
hadoop@ubuntu16:~$ hadoop version Hadoop 2.8.0 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 91f2b7a13d1e97be65db92ddabc627cc29ac0009 Compiled by jdu on 2017-03-17T04:12Z Compiled with protoc 2.5.0 From source with checksum 60125541c2b3e266cbf3becc5bda666 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.8.0.jar
配置hadoop伪分布式
配置hadoop伪分布式需要修改相关配置文件:hadoop-env.xml/core-site.xml/hdfs-site.xml
hadoop配置文件位置:hadoop主目录下的/etc/hadoop,如下
hadoop@ubuntu16:/usr/local/hadoop/etc/hadoop$ ls
capacity-scheduler.xml httpfs-env.sh mapred-env.sh
configuration.xsl httpfs-log4j.properties mapred-queues.xml.template
container-executor.cfg httpfs-signature.secret mapred-site.xml
core-site.xml httpfs-site.xml mapred-site.xml.template
hadoop-env.cmd kms-acls.xml slaves
hadoop-env.sh kms-env.sh ssl-client.xml.example
hadoop-metrics.properties kms-log4j.properties ssl-server.xml.example
hadoop-metrics2.properties kms-site.xml yarn-env.cmd
hadoop-policy.xml log4j.properties yarn-env.sh
hdfs-site.xml mapred-env.cmd yarn-site.xml
修改相应的配置文件
打开hadoop-env.sh
hadoop@ubuntu16:/usr/local/hadoop/etc/hadoop$ vi hadoop-env.sh找到以下位置,把java目录修改为自己的主目录
# The java implementation to use. export JAVA_HOME=${JAVA_HOME}打开core-site.xml,并添加configuration内容
hadoop@ubuntu16:/usr/local/hadoop/etc/hadoop$ vi core-site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
- 打开hdfs-site.xml,并添加configuration内容
hadoop@ubuntu16:/usr/local/hadoop/etc/hadoop$ vi hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration>
格式化namenode
hadoop@ubuntu16:~$ hdfs namenode -format
启动NameNode和DataNode进程
hadoop@ubuntu16:~$ start-dfs.sh Starting namenodes on [localhost] localhost: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-ubuntu16.out localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-ubuntu16.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-secondarynamenode-ubuntu16.out hadoop@ubuntu16:~$ jps 41749 NameNode 42203 Jps 42092 SecondaryNameNode 41903 DataNode
访问web界面
输入主机ip:50070,访问主界面,如下
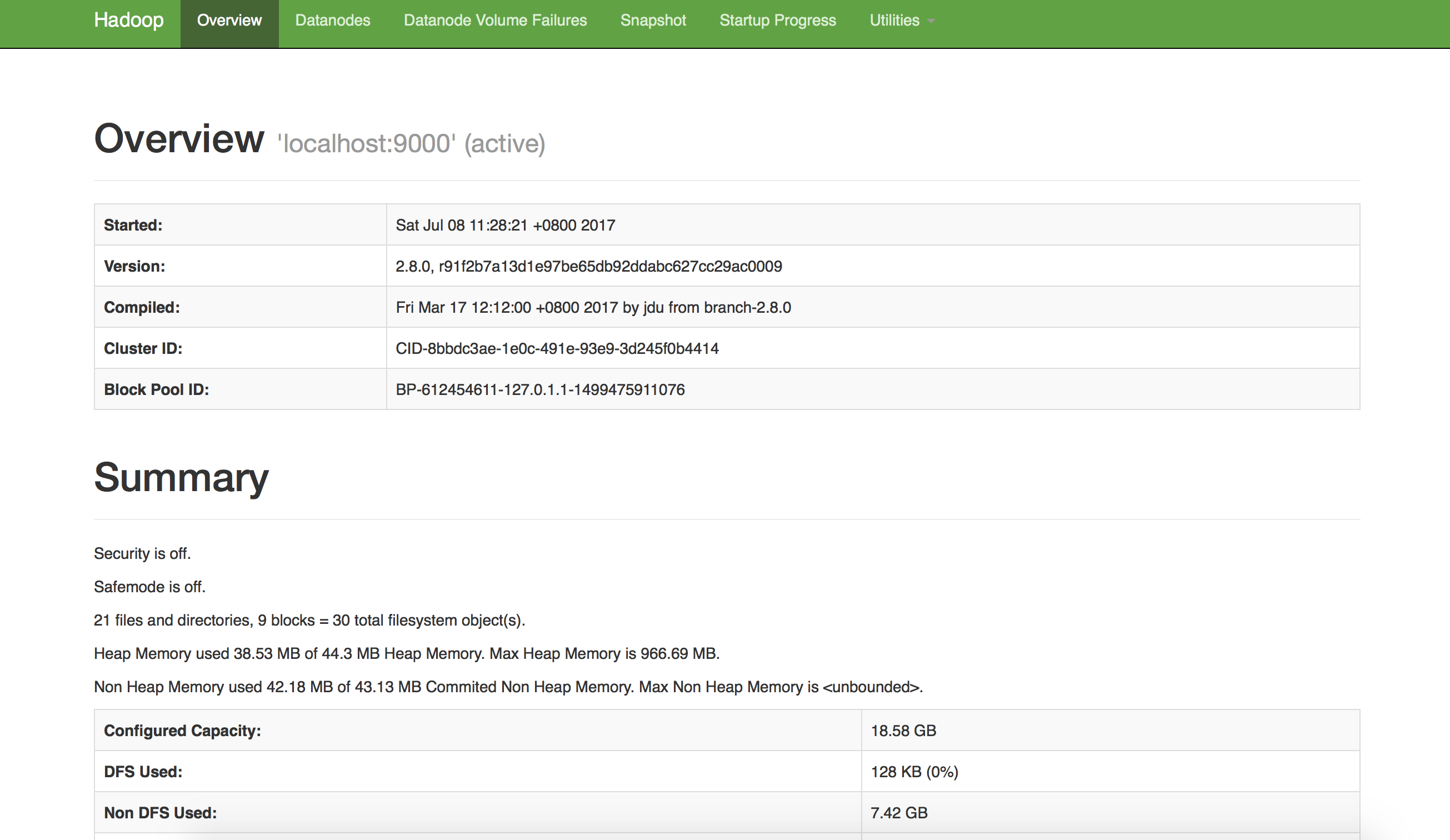
运行hadoop实例
创建目录
hadoop@ubuntu16:~$ hdfs dfs -mkdir /user/hadoop hadoop@ubuntu16:~$ hdfs dfs -mkdir input将本地文件拷贝到hdfs下input目录(发现有警告信息,目前还没有找到解决方法,不管不影响运行结果)
hadoop@ubuntu16:~$ hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml input 17/07/08 16:00:09 WARN hdfs.DataStreamer: Caught exception java.lang.InterruptedException at java.lang.Object.wait(Native Method) at java.lang.Thread.join(Thread.java:1252) at java.lang.Thread.join(Thread.java:1326) at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:927) at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:578) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:755) 17/07/08 16:00:09 WARN hdfs.DataStreamer: Caught exception java.lang.InterruptedException at java.lang.Object.wait(Native Method) at java.lang.Thread.join(Thread.java:1252) at java.lang.Thread.join(Thread.java:1326) at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:927) at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:578) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:755) 17/07/08 16:00:09 WARN hdfs.DataStreamer: Caught exception java.lang.InterruptedException at java.lang.Object.wait(Native Method) at java.lang.Thread.join(Thread.java:1252) at java.lang.Thread.join(Thread.java:1326) at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:927) at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:578) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:755) 17/07/08 16:00:09 WARN hdfs.DataStreamer: Caught exception java.lang.InterruptedException at java.lang.Object.wait(Native Method) at java.lang.Thread.join(Thread.java:1252) at java.lang.Thread.join(Thread.java:1326) at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:927) at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:578) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:755) hadoop@ubuntu16:~$ hdfs dfs -ls Found 1 items drwxr-xr-x - hadoop supergroup 0 2017-07-08 16:00 input hadoop@ubuntu16:~$ hdfs dfs -ls input Found 8 items -rw-r--r-- 1 hadoop supergroup 4942 2017-07-08 16:00 input/capacity-scheduler.xml -rw-r--r-- 1 hadoop supergroup 1032 2017-07-08 16:00 input/core-site.xml -rw-r--r-- 1 hadoop supergroup 9683 2017-07-08 16:00 input/hadoop-policy.xml -rw-r--r-- 1 hadoop supergroup 1079 2017-07-08 16:00 input/hdfs-site.xml -rw-r--r-- 1 hadoop supergroup 620 2017-07-08 16:00 input/httpfs-site.xml -rw-r--r-- 1 hadoop supergroup 3518 2017-07-08 16:00 input/kms-acls.xml -rw-r--r-- 1 hadoop supergroup 5546 2017-07-08 16:00 input/kms-site.xml -rw-r--r-- 1 hadoop supergroup 794 2017-07-08 16:00 input/yarn-site.xml运行自带实例
hadoop@ubuntu16:~$ hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar grep input output ‘dfs[a-z.]+’查看运行结果
hadoop@ubuntu16:~$ hdfs dfs -ls Found 2 items drwxr-xr-x - hadoop supergroup 0 2017-07-08 16:00 input drwxr-xr-x - hadoop supergroup 0 2017-07-08 16:10 output hadoop@ubuntu16:~$ hdfs dfs -ls output Found 2 items -rw-r--r-- 1 hadoop supergroup 0 2017-07-08 16:10 output/_SUCCESS -rw-r--r-- 1 hadoop supergroup 77 2017-07-08 16:10 output/part-r-00000 hadoop@ubuntu16:~$ hdfs dfs -cat output/* 1 dfsadmin 1 dfs.replication 1 dfs.namenode.name.dir 1 dfs.datanode.data.dir
NOTE: 再次运行前,需要删除掉output目录,否则会报错
配置yarn
打开yarn-site.xml,并添加如下configuration
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>启动ResourceManager和NodeManager进程,jps可以看出比单独启动start-dfs.sh 多出来两个进程
hadoop@ubuntu16:/usr/local/hadoop/etc/hadoop$ start-yarn.sh starting yarn daemons starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-resourcemanager-ubuntu16.out localhost: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-ubuntu16.out hadoop@ubuntu16:/usr/local/hadoop/etc/hadoop$ jps 46788 SecondaryNameNode 51397 NodeManager 46598 DataNode 46443 NameNode 51724 Jps 51276 ResourceManager启动历史进程
hadoop@ubuntu16:/usr/local/hadoop/etc/hadoop$ mr-jobhistory-daemon.sh start historyserver starting historyserver, logging to /usr/local/hadoop/logs/mapred-hadoop-historyserver-ubuntu16.out访问web界面
输入主机ip:8088,访问主界面,如下
关闭所有进程,和开启顺序相反
hadoop@ubuntu16:~$ mr-jobhistory-daemon.sh stop historyserver stopping historyserver hadoop@ubuntu16:~$ stop-yarn.sh stopping yarn daemons stopping resourcemanager localhost: stopping nodemanager localhost: nodemanager did not stop gracefully after 5 seconds: killing with kill -9 no proxyserver to stop hadoop@ubuntu16:~$ stop-dfs.sh Stopping namenodes on [localhost] localhost: stopping namenode localhost: stopping datanode Stopping secondary namenodes [0.0.0.0] 0.0.0.0: stopping secondarynamenode



